EZThrottle: Making Failure Boring Again
You know how Cloudflare sits in front of your app and routes traffic to the fastest, healthiest origin?
EZThrottle does that for your outbound API calls.
EZThrottle is a multi-region HTTP proxy for external APIs.
Your app calls EZThrottle. EZThrottle routes to the fastest, healthiest region of the destination API. If OpenAI us-east-1 is slow, we route to eu-west-1. If both are slow, we race them and take the fastest.
Why "Just Retry on the Client" Doesn't Work
Here's the scenario where client-side retry completely fails:
Scenario: Partial Regional Outage
- You're calling
api.openai.com - DNS routes you to us-east-1 (closest region)
- us-east-1 is having issues (slow, intermittent 500s)
- But it's not fully DOWN (some requests work)
With client-side retry:
@retry(stop=stop_after_attempt(3))
def call_openai():
return requests.post("https://api.openai.com/...")What happens:
- Request 1 → us-east-1 (slow, 10 seconds, times out)
- Retry 1 → us-east-1 again (DNS still routes here, still slow)
- Retry 2 → us-east-1 again (still slow)
- After 30 seconds: FAIL
User experience: 30 second wait, then failure.
With EZThrottle:
result = (
Step(client)
.url("https://api.openai.com/...")
.regions(["iad", "lax", "ord"])
.execution_mode("race")
.execute()
)What happens:
- Request sent to all 3 regions simultaneously
- us-east-1 is slow... but lax responds in 100ms
- lax wins the race, us-east-1 cancelled
- Total time: 100ms
User experience: 100ms, success.
The Comparison:
Client-side retry: 30 seconds → failure
EZThrottle: 100ms → success
Client-side retry can't solve this. It doesn't have visibility into regional health. It just keeps hitting the same slow region.
Region Racing: The Feature You Didn't Know You Needed
This is EZThrottle's killer feature. Send the same request to multiple regions simultaneously. Fastest one wins. Cancel the rest.
from ezthrottle import EZThrottle, Step, StepType
client = EZThrottle(api_key="your_api_key")
result = (
Step(client)
.url("https://api.stripe.com/charges")
.method("POST")
.type(StepType.PERFORMANCE)
.regions(["iad", "lax", "ord"])
.execution_mode("race")
.webhooks([{"url": "https://your-app.com/webhook"}])
.execute()
)What this gives you:
- Survive partial outages - one region slow? Take another
- Sub-second failover - no waiting for timeouts
- Automatic regional health detection - EZThrottle learns which regions are healthy
- You only pay for the winner - losers are cancelled
This isn't something a retry library can do. Client-side code can't race requests across regions it doesn't know exist.
Also: Coordinated Retries (The Bonus Feature)
Once you're routing through EZThrottle, you also get coordinated retry logic across your entire fleet.
The problem with client-side retries at scale:
- 1000 workers hit OpenAI's rate limit
- 1000 workers all retry independently
- Thundering herd → retry storm → cascading failure
With EZThrottle, one worker discovers the rate limit, and the shared state updates for everyone. No storm.
N clients × 3 retries = 3N wasted requests.
EZThrottle: ~1.
The DIY Retry Queue: A Horror Story
"What if we just build a retry queue ourselves?"
Let me tell you how this goes. I've seen it. I've lived it.
Month 1: You have N clients fighting for quota Q on a single API.
Retry storms are killing you. Someone suggests a centralized queue.
Cost: $15k/month in wasted compute (workers retrying instead of working)
Month 2: You build the queue. It works! Requests flow through one bottleneck,
rate limiting is enforced, retries are controlled. Ship it. Victory beer.
Cost drops to $3k/month. But now you're paying $2k/month for SQS.
Month 3: You add more URLs. Five APIs. Ten APIs. Twenty.
One queue. Twenty different rate limits. Some APIs allow 100 RPS, some allow 2.
The fast ones starve behind the slow ones. Everything is unbearable.
Latency: 5 seconds per request (was 200ms). Customers complaining.
Month 6: "We need queue-per-URL." You spin up a fleet of workers.
Each URL gets its own queue with its own rate limit. The architecture diagram now
requires a team to maintain.
Cost: $8k/month infra + 1 DevOps engineer ($150k/year)
Month 9: The CTO signs a 10x contract. Traffic explodes.
Your queue-per-URL workers can't keep up. The single-server architecture
doesn't scale. You miss your son's birthday debugging Redis connection pools.
Cost: $25k/month infra + 2 more engineers ($300k/year)
Month 12: You cancel your vacation. Again.
The team implements Zookeeper for coordination, Redis for state,
and Kubernetes for orchestration. Six months of infrastructure work
to solve a problem that has nothing to do with your actual product.
Cost: $50k/month infra + team of 3 engineers ($500k/year)
Serverless should be painless and opsless—not managing a fucking factory of queues.
Month 14: The CTO heard about this thing called EZThrottle. "Can we go global? Multi-region?" You stare at your Zookeeper cluster. Managed Redis alone is $1,000/month. Just for the storage layer. You think about your original job description. You update your LinkedIn.
Or with EZThrottle:
$50-500/month. Zero infrastructure. Multi-region included. Ship in an afternoon.
pip install ezthrottleWhy This Is Natural for the BEAM
Here's the thing: queue-per-URL is a nightmare in most languages.
In the BEAM? It's the obvious design.
Erlang was built for telephone switches. A phone switch doesn't have "one queue for all calls." It has a process per call. A process per connection. A process per subscriber. The actor model makes this trivial—spawn a process, it handles its own state, it fails in isolation without taking down its neighbors.
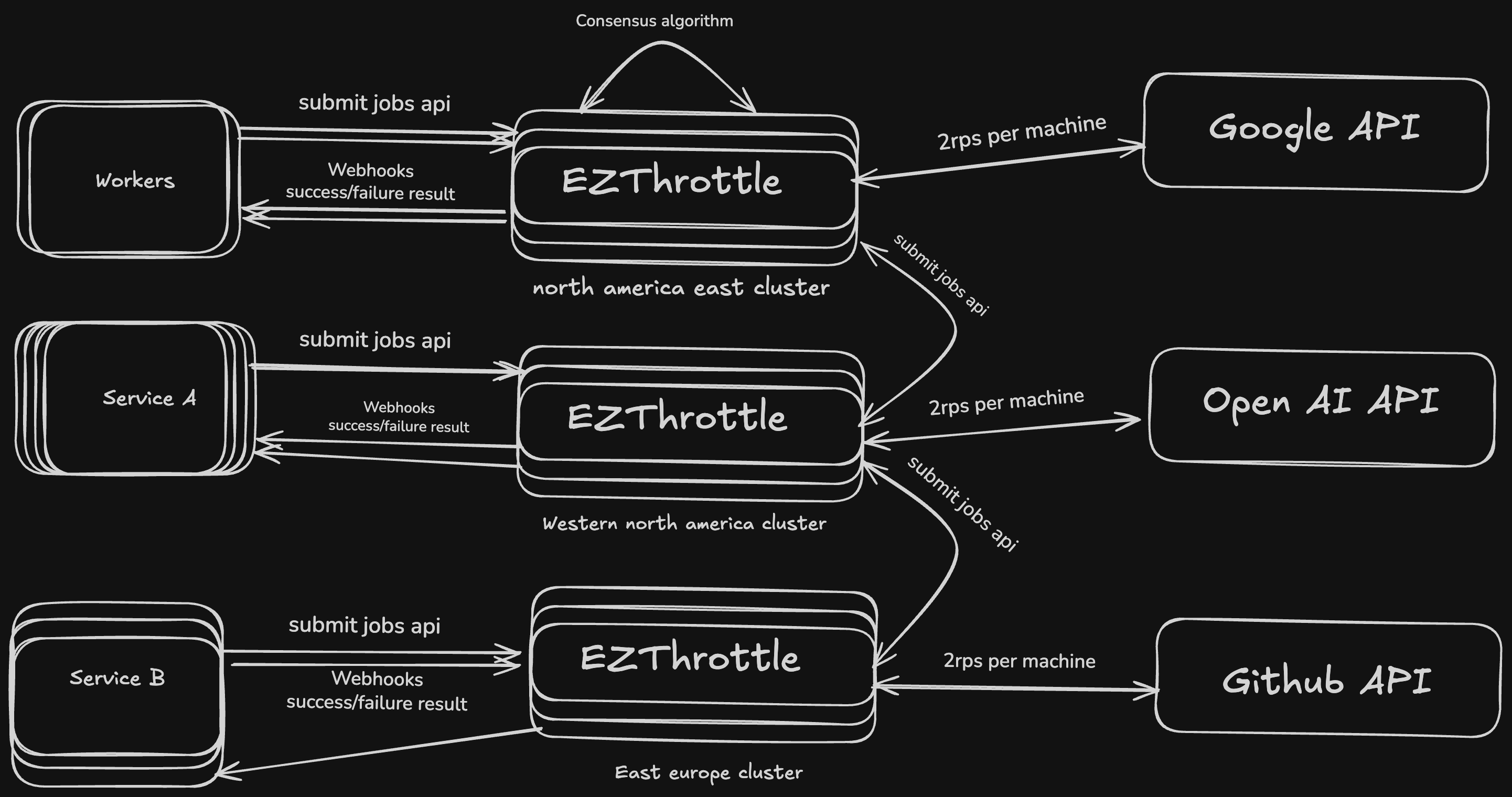
EZThrottle does the same thing for URLs. Each destination gets its own process. Its own rate limit tracking. Its own retry state. Millions of them, running concurrently, coordinating through message passing instead of shared memory locks.
And because EZThrottle runs on Fly.io, forwarding a request to another region is just an API call. The Fly proxy handles the hard parts—anycast routing, WireGuard tunnels between regions, health checking.
What takes six months of Zookeeper and Redis in other stacks is a weekend of Gleam code on the BEAM.
The Simple Idea That Changed Everything
EZThrottle is built around one opinionated idea:
Retries shouldn't be independent.
Instead of thousands of machines panicking at once, EZThrottle coordinates failure in one place.
All outbound requests flow through EZThrottle, which keeps track of:
- how fast a destination can actually handle traffic
- which regions are healthy
- when it's time to slow down or reroute
Once failure becomes shared state, it stops being chaos.
Why This Runs on the BEAM (and Why That Matters)
EZThrottle is written in Gleam and runs on Erlang/OTP.
That choice wasn't about trends—it was about survival.
The BEAM was designed for:
- massive concurrency
- message passing instead of shared memory
- processes that fail without taking everything else down
- distributed coordination that doesn't fall apart under load
EZThrottle isn't trying to make one HTTP call fast. It's trying to coordinate millions of them safely. This is exactly what the BEAM is good at.
This isn't theoretical. BEAM powers telephone switches that handle millions of calls with 99.9999999% uptime — nine nines. When "down" means emergency calls don't connect, you build different. EZThrottle inherits that DNA.
429s Aren't Errors — They're Signals
A 429 isn't your API yelling at you. It's your API asking you to slow down.
Most systems ignore that signal and keep retrying anyway.
EZThrottle takes the hint.
The boring default (on purpose)
By default, EZThrottle sends 2 requests per second per target domain.
Not globally. Not per account. Per destination.
Examples:
api.stripe.com→ 2 RPSapi.openai.com→ 2 RPSapi.anthropic.com→ 2 RPS
This default exists to prevent your infrastructure from accidentally turning into a distributed denial-of-service attack.
It smooths bursts, stops retry storms, and keeps upstreams healthy.
Yes, it's conservative. That's the point.
The real insight: you can tune traffic with a header change instead of deploying new servers. Traditional scaling means spinning up infrastructure, updating configs, waiting for DNS. EZThrottle scaling is a code change. Your ops team will thank you.
How Rate Limits Work
EZThrottle enforces rate limits automatically. Clients don't control the rate — the service maintainer does.
If you're building an API and want to tell EZThrottle how fast you can handle traffic, respond with these headers:
X-EZTHROTTLE-RPS: 5
X-EZTHROTTLE-MAX-CONCURRENT: 10EZThrottle reads these and adjusts. No client configuration needed — rate limiting happens at the infrastructure layer.
The important part isn't the knobs. It's this:
Rate limiting becomes shared state instead of a thousand sleep() calls.
When Things Actually Break (5xx and Outages)
Regions go down. Configs break. Dependencies flake out.
EZThrottle assumes this will happen.
When a request fails with a 5xx or times out:
- that region is marked as unhealthy
- traffic is rerouted to healthy regions
- optionally, requests are raced across regions
The result isn't "everything is perfect."
The result is: a small latency bump instead of a full outage.
Bidirectional protection:
Your customers are protected from YOUR outages — if your region goes down, requests route elsewhere. And you're protected from your API providers having outages — requests distribute across healthy regions. A load balancer can't do this. It just distributes traffic to your servers. EZThrottle coordinates across regions and providers.
Two Ways to Use EZThrottle
Not every request needs the same level of reliability. That's why EZThrottle supports two modes:
PERFORMANCE Mode
Always route through EZThrottle. Every request gets multi-region racing, automatic retries, and webhook delivery.
Use when: Reliability > cost. Payment processing, critical notifications, anything where failure means lost revenue.
result = (
Step(client)
.url("https://api.stripe.com/charges")
.type(StepType.PERFORMANCE)
.regions(["iad", "lax", "ord"])
.execution_mode("race")
.webhooks([{"url": "https://your-app.com/webhook"}])
.execute()
)FRUGAL Mode
Execute locally first. Only forward to EZThrottle when you hit rate limits or errors. Pay nothing when things work.
Use when: Cost > reliability. Analytics, logging, non-critical APIs with 95%+ success rates.
result = (
Step(client)
.url("https://api.example.com/endpoint")
.type(StepType.FRUGAL)
.fallback_on_error([429, 500, 502, 503])
.webhooks([{"url": "https://your-app.com/webhook"}])
.execute()
)Most teams start with FRUGAL for non-critical paths, then flip to PERFORMANCE for anything that wakes them up at night.
The Tradeoff EZThrottle Makes (On Purpose)
EZThrottle prioritizes:
- predictable completion
- bounded failure
- coordinated recovery
Over:
- maximum burst throughput
- raw, unbounded speed
If you want every request to fire as fast as possible, EZThrottle isn't for you.
If you want to stop waking up to retry storms, it probably is.
"But Isn't This a Single Point of Failure?"
This is the second question everyone asks. It's a fair concern.
But here's the thing: EZThrottle isn't a dependency. It's a reliability layer.
Every SDK ships with forward_or_fallback().
If EZThrottle is unreachable, you fall back to whatever you were doing before:
from ezthrottle import EZThrottle
import requests
client = EZThrottle(api_key="your_api_key")
# If EZThrottle is down, fall back to direct HTTP call
result = client.forward_or_fallback(
fallback=lambda: requests.post(
"https://api.stripe.com/charges",
headers={"Authorization": "Bearer sk_live_..."},
json={"amount": 1000}
),
url="https://api.stripe.com/charges",
method="POST",
headers={"Authorization": "Bearer sk_live_..."},
body='{"amount": 1000}'
)If EZThrottle goes down:
- Your requests still go through (via fallback)
- You lose the coordination features temporarily
- You're back to independent retries until EZThrottle recovers
That's the worst case: you're back to where you started.
EZThrottle failing doesn't break your system. It just means you lose the extra reliability—temporarily.
What EZThrottle Is (and Isn't)
EZThrottle is:
- a reliable HTTP transport
- a coordination layer for outbound requests
- a way to make failure boring again
EZThrottle is not:
- a database
- a general compute platform
- a replacement for business logic
Requests live in memory, move through the system, and disappear. There's nothing to mine, leak, or hoard.
Who Needs This?
You probably need EZThrottle if:
- You're making >1M API calls/month to external services
- You have >50 workers/instances calling the same APIs
- You've been rate limited and it cascaded into an outage
- You're managing queues just to handle retries
- You're calling AI APIs (OpenAI, Anthropic, etc.) at scale
- You're building AI agents that make dozens of API calls per workflow
You probably don't need this if:
- Single server making occasional API calls
- <10k requests/month
- You only call APIs you control (not external rate limits)
- Exponential backoff is genuinely working fine for you
Why This Matters
Most infrastructure complexity exists to compensate for unreliable networks.
EZThrottle doesn't eliminate failure.
It eliminates panic.
By turning retries, rate limits, and region health into shared state, it gives you something rare in distributed systems:
Predictable behavior when things go wrong.
But making failure boring isn't enough. Engineers need to ship features, not fight infrastructure. The real question is: what can you build when Layer 7 is reliable?
Fallback racing across providers. Webhook fanout with quorum. Workflows that replace Step Functions. Legacy code wrappers that onboard in minutes. Event-driven architecture without SQS.
Continue reading: Serverless 2.0 — RIP Operations →